点击量:866
之前机器学习系列的所有文章讲得都是监督学习(supervised learning),今天我们来讲一讲无监督学习(unsupervised learning)。本文覆盖Coursera Machine Learning Week 8的内容,将会介绍一个无监督学习算法-K均值聚类算法(K-means Algorithm for clustering)
K-means Algorithm
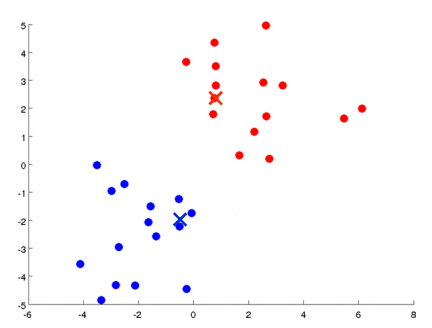
无监督学习和监督学习最大的不同是他不需要对样本数据集打标签,而是只根据样本数据分析其内在规律而自动进行簇分类。直观意义上的理解:比如我们有这样一堆样本数据,他的分布如下图:
事先我们并没有对样本数据打标签以标识它属于哪个分类,通过聚类算法,我们希望这堆看上去很容易被分开的数据能够自动分类。那么具体怎么做呢?
对于K个分类的聚类算法而言,步骤如下:
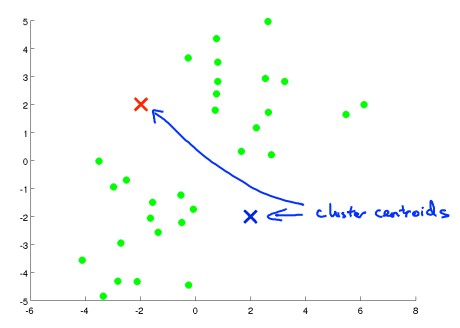
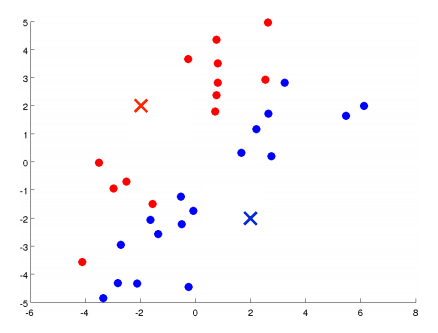
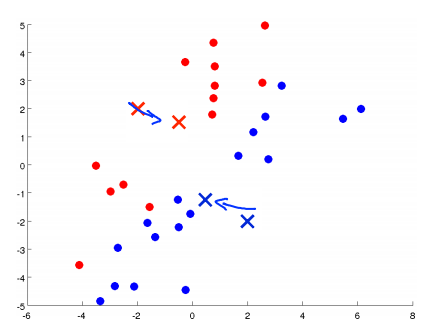
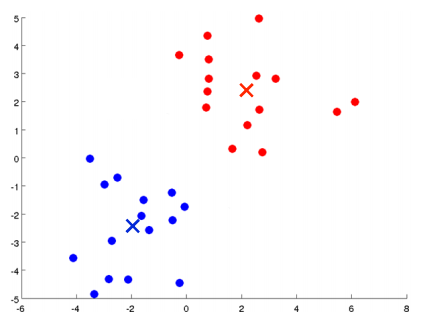
根据上述描述,我们形式化地总结下K均值算法:
输入:

算法:

Optimization Objective(优化目标)
遇到优化问题我们总是得先找一个优化目标函数,然后不断降低该函数的值,最后得到最优解。那么K均值算法的目标函数是什么呢?
我们先定义一组变量:
于是我们定义目标函数:
$$J(c^{\left ( 1 \right )},…,c^{\left ( m \right )},\mu _{1},…\mu _{k}) = \frac{1}{m} \sum_{i=1}^{m}\left \| x^{\left ( i \right )} – \mu _{c^{\left ( i \right )}} \right \|^{2}$$
那么我们的优化目标就是求得该值的最小值:
$$min _{c^{\left ( 1 \right )},…,c^{\left ( m \right )},\mu _{1},…\mu _{k}}J(c^{\left ( 1 \right )},…,c^{\left ( m \right )},\mu _{1},…\mu _{k})$$
上面的各种变量公式看似复杂,其实就是一个目的:求得所有样本点到其所属簇的距离的平方和最小。
Random Initialization(随机初始化)
该算法的第一步是随机初始化K个簇中心点,具体地,我们可以随机选取K个样本作为簇中心点。此外,最后的分类结果跟初始簇中心点的选择有关系,所以我们可以多次随机以获得最小的目标函数。
如何选择簇的数量?(Choosing the Number of Clusters)
在现实工作中,簇数K的选择往往是不确定的,但是我们可以通过一些辅助的方法来帮助我们做决定。这里介绍一种方法:“肘部法则(Elbow Method)”。具体地,画出代价J关于簇数K的函数图,如下图所示:
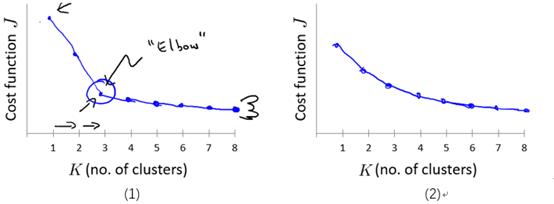
在左图中,我们很明显地看到了一个“肘点”,那么我们可以选择K=3。但是更多时候我们得到的可能是右边的函数图像,并不存在明显的肘点,所以这种方法也仅仅是辅助参考,并不能完全决定如何选取K的值。
课后编程作业已经上传至本人GitHub,如有需要可以参考,但请遵守课堂准则,不要抄袭。
